Web Scraping & RAG Pipeline
Pipeline de scraping intelligent avec Crawl4AI et RAG avancé pour interroger n'importe quel site web
Technologies
Description
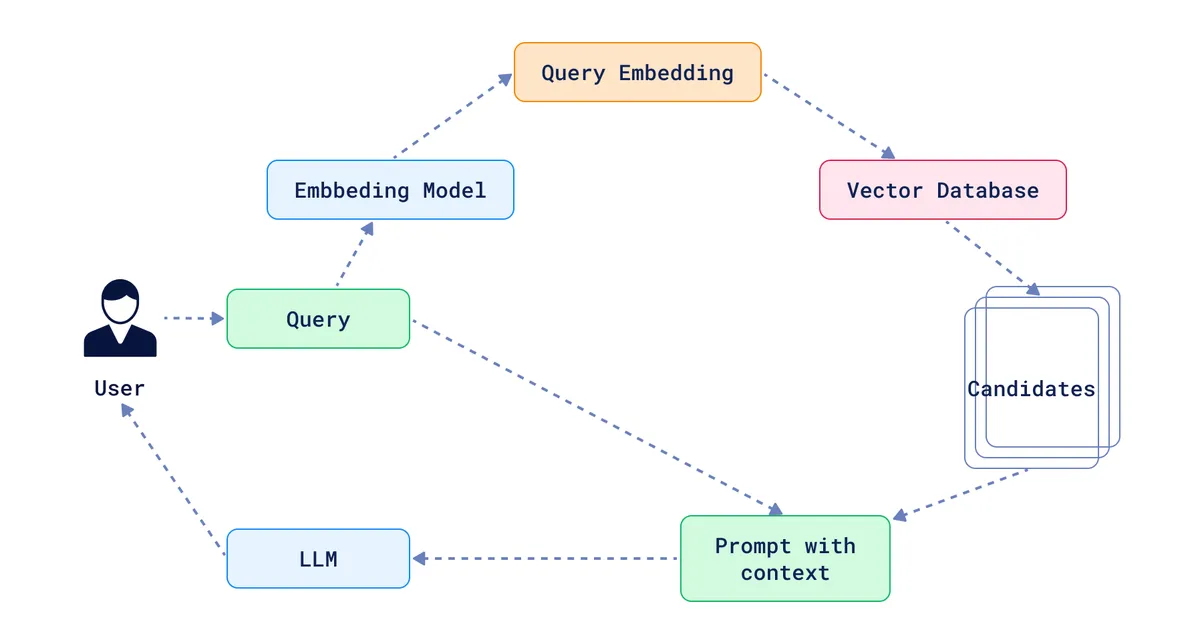
Pipeline complet permettant de scraper n’importe quel site web et de l’interroger via RAG avancé. L’objectif : transformer des données web non structurées en une base de connaissances interrogeable par langage naturel.
Architecture
flowchart LR
A[🌐 URL] --> B[Crawl4AI]
B --> C[LLM Extraction]
C --> D[Chunking]
D --> E[Embeddings]
E --> F[(Vector DB)]
F --> G[RAG Agent]
G --> H[💬 Response]
Scraping intelligent avec Crawl4AI
Utilisation de Crawl4AI, un crawler open-source optimisé pour les LLMs :
- LLM Extraction : Extraction de données structurées via prompts, sans CSS selectors fragiles qui cassent à chaque mise à jour du site
- Markdown optimisé : Sortie directement exploitable par les LLMs (nettoyage automatique du HTML)
- Support JavaScript : Rendu complet des sites React, Vue, Angular via navigateur headless
- Gestion RGPD : Acceptation automatique des cookies et popups
- Deep crawl : Exploration récursive avec scoring de pertinence des pages
Vectorisation
Le contenu scrapé est transformé en vecteurs pour la recherche sémantique :
| Composant | Configuration |
|---|---|
| Chunking | Recursive character splitter (1000 chars, 200 overlap) |
| Embeddings | OpenAI text-embedding-3-small (1536 dimensions) |
| Vector Store (dev) | ChromaDB (local, rapide) |
| Vector Store (prod) | Supabase pgvector (scalable, requêtes SQL) |
Le chunking avec overlap permet de préserver le contexte entre les segments :
flowchart LR
Doc[📄 Document] --> C1[Chunk 1<br/>1000 chars]
Doc --> C2[Chunk 2<br/>1000 chars]
Doc --> C3[Chunk 3<br/>1000 chars]
C1 -.->|200 chars overlap| C2
C2 -.->|200 chars overlap| C3
Techniques RAG avancées
Au-delà du RAG basique (retrieve → generate), plusieurs techniques améliorent la qualité des réponses :
HyDE (Hypothetical Document Embeddings)
Générer un document hypothétique répondant à la question, puis rechercher des documents similaires à cette réponse idéale :
flowchart TB
Q[❓ Query utilisateur] --> LLM[LLM génère document hypothétique]
LLM --> HDoc[📄 Document idéal fictif]
HDoc --> Emb[Embedding du doc hypothétique]
Emb --> Search[Recherche similarité]
Search --> Results[📚 Documents pertinents]
Query Augmentation & Multiple Query Generation
- Query Augmentation : Enrichir la requête utilisateur avec des synonymes et reformulations via LLM avant l’embedding
- Multiple Query Generation : Générer plusieurs variantes de la requête pour augmenter le recall
Reciprocal Rank Fusion (RRF)
Combiner les résultats de plusieurs retrievers avec pondération intelligente :
flowchart LR
Q[Query] --> R1[Retriever 1]
Q --> R2[Retriever 2]
Q --> R3[Retriever 3]
R1 --> |Rank A| RRF[🔀 RRF Fusion]
R2 --> |Rank B| RRF
R3 --> |Rank C| RRF
RRF --> Final[Score combiné pondéré]
Re-ranking
Affiner le classement final avec un modèle cross-encoder pour améliorer la précision.
Agentic RAG
L’approche “Agentic RAG” va au-delà du pipeline linéaire classique. Un agent LLM orchestre dynamiquement le processus de retrieval :
flowchart TB
Q[Query] --> Agent[🤖 Agent RAG]
Agent --> Decide{Stratégie ?}
Decide --> |Reformuler| Rewrite[Query Rewriting]
Decide --> |Multi-query| Multi[Générer variantes]
Decide --> |Direct| Retrieve[Retrieval]
Rewrite --> Retrieve
Multi --> Retrieve
Retrieve --> Eval{Résultats suffisants ?}
Eval --> |Non| Agent
Eval --> |Oui| Generate[Génération réponse]
Generate --> Response[💬 Réponse finale]
L’agent peut :
- Décider de la stratégie : Choisir entre retrieval direct, reformulation, ou génération de requêtes multiples selon la complexité de la question
- Auto-évaluer : Juger si les documents récupérés sont suffisants pour répondre
- Itérer : Relancer une recherche avec une stratégie différente si les résultats sont insuffisants
- Orchestrer : Combiner plusieurs techniques (HyDE + RRF + re-ranking) de manière adaptative
Stack technique
- Scraping : Python, Crawl4AI, Playwright
- Vectorisation : LangChain, ChromaDB, Supabase pgvector
- LLM : OpenAI API (GPT-4, text-embedding-3-small)
- Orchestration : Python asyncio pour le crawl parallèle
Défis rencontrés
- Sites dynamiques : Certains sites chargent le contenu via JavaScript avec infinite scroll, nécessitant une stratégie de scroll automatique
- Rate limiting : Implémentation de délais adaptatifs et rotation de headers pour éviter les blocages
- Qualité du chunking : Trouver le bon équilibre taille/overlap pour préserver le contexte sans créer de doublons
- Coût des embeddings : Optimisation du nombre de tokens en filtrant le contenu non pertinent avant vectorisation
Résultats
- Capable de scraper et indexer des sites de 50+ pages en quelques minutes
- Réponses contextuelles précises grâce aux techniques RAG avancées (HyDE améliore significativement la pertinence)
- Pipeline réutilisable pour différents cas d’usage : documentation technique, sites e-commerce, bases de connaissances