LLM en PyTorch
Création et entrainement d'un modèle type GPT-2 en PyTorch pur
Technologies
Description
Créer un LLM (Large Language Model) m’a toujours intéressé, et le livre Build a Large Language Model de Sebastian Raschka était l’occasion parfaite pour moi de revisiter la structure des Transformers en PyTorch. On y apprend comment transformer des mots en tokens, comment coder et utiliser la partie décodeur d’un Transformer (en PyTorch pur, avec des formules mathématiques) pour générer de nouveaux tokens un par un, comment préparer un dataset pour le pre-training, comment fine-tuner un modèle sur des données et comment implémenter le RLHF (Reinforcement Learning with Human Feedback) pour qu’un LLM suive des instructions.
Fonctionnalités
- Tokenisation : Conversion de texte en tokens avec un vocabulaire personnalisé
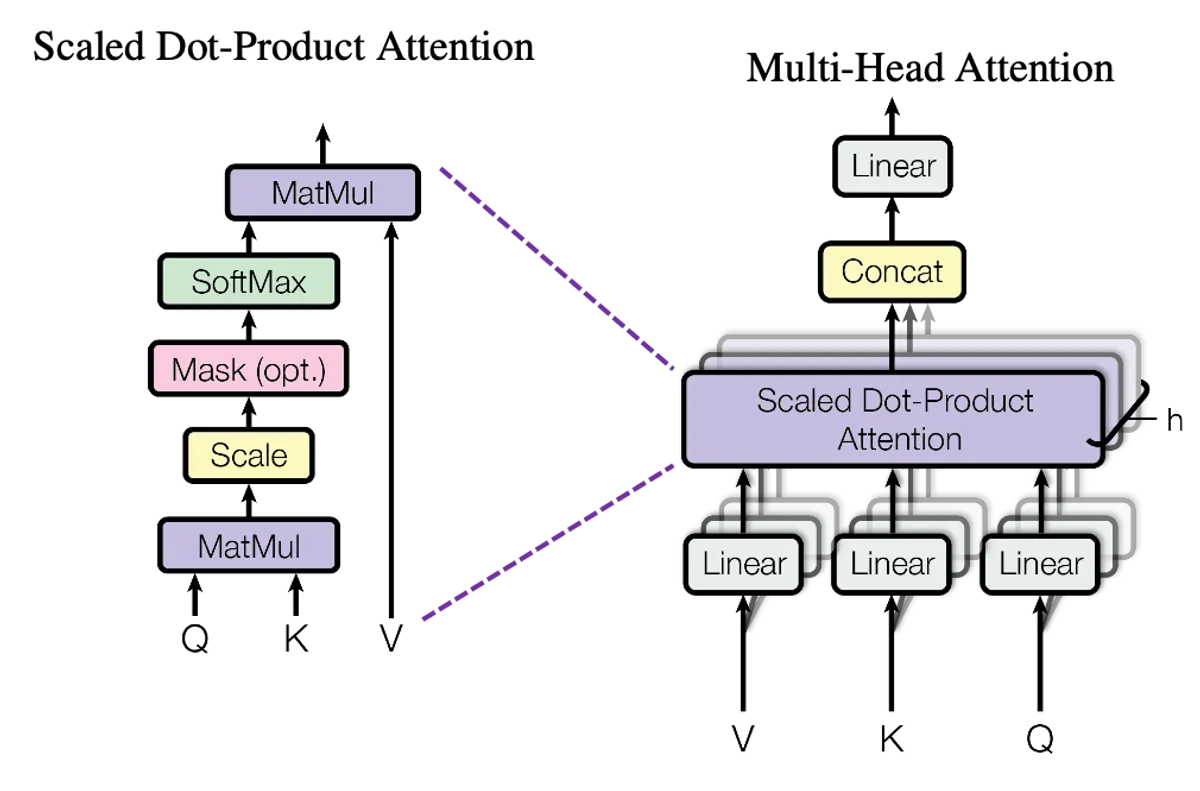
- Architecture Transformer : Implémentation complète du décodeur (attention multi-têtes, couches de normalisation, feed-forward) en PyTorch pur
- Pre-training : Préparation de datasets et entraînement du modèle sur la prédiction du prochain token
- Fine-tuning : Adaptation du modèle pré-entraîné sur des tâches spécifiques
- RLHF : Implémentation du Reinforcement Learning with Human Feedback pour l’alignement du modèle
Défis rencontrés
- Compréhension du mécanisme d’attention : Visualiser comment les matrices Q, K, V interagissent et pourquoi la division par √d_k est nécessaire pour la stabilité numérique a demandé plusieurs lectures et expérimentations
- Debugging de l’entraînement : Identifier pourquoi la loss stagnait ou explosait, ajuster les hyperparamètres (learning rate, batch size, warmup steps) de manière empirique
- Contraintes matérielles : Avec une
RTX 5070 Ti, j’ai dû optimiser l’utilisation de la mémoireGPUet limiter la taille du modèle et des batches - Gestion du gradient : Comprendre et implémenter le gradient accumulation pour simuler des batch sizes plus grands malgré les limitations mémoire
Architecture du modèle
Le modèle implémenté suit l’architecture GPT-2 Small d’OpenAI :
| Paramètre | Valeur |
|---|---|
| Paramètres | 124M |
| Couches (layers) | 12 |
| Dimension des embeddings | 768 |
| Têtes d’attention | 12 |
| Contexte max | 1024 tokens |
| Vocabulaire | ~50k tokens (BPE) |
Cette architecture est identique à celle de GPT-3, mais à une échelle beaucoup plus réduite (GPT-3 compte 175 milliards de paramètres contre 124 millions ici), ce qui la rend entraînable sur du matériel grand public.
Résultats
Le modèle a été pré-entraîné sur le corpus de Shakespeare (~1 Mo de texte), ce qui lui donne un style d’écriture particulier en anglais élisabéthain :
- Génération de texte cohérent : Le modèle produit des phrases grammaticalement correctes qui imitent le style shakespearien, avec des tournures archaïques (“thou”, “hath”, “wherefore”)
- Suivi d’instructions : Après fine-tuning, le modèle répond aux prompts de manière contextuelle
- Limites : La taille réduite du dataset et du modèle limite la diversité et la profondeur des réponses — le modèle excelle dans son domaine étroit mais ne généralise pas à d’autres styles ou sujets