Web Scraping & RAG Pipeline
Intelligent scraping pipeline with Crawl4AI and advanced RAG to query any website
Tech Stack
Description
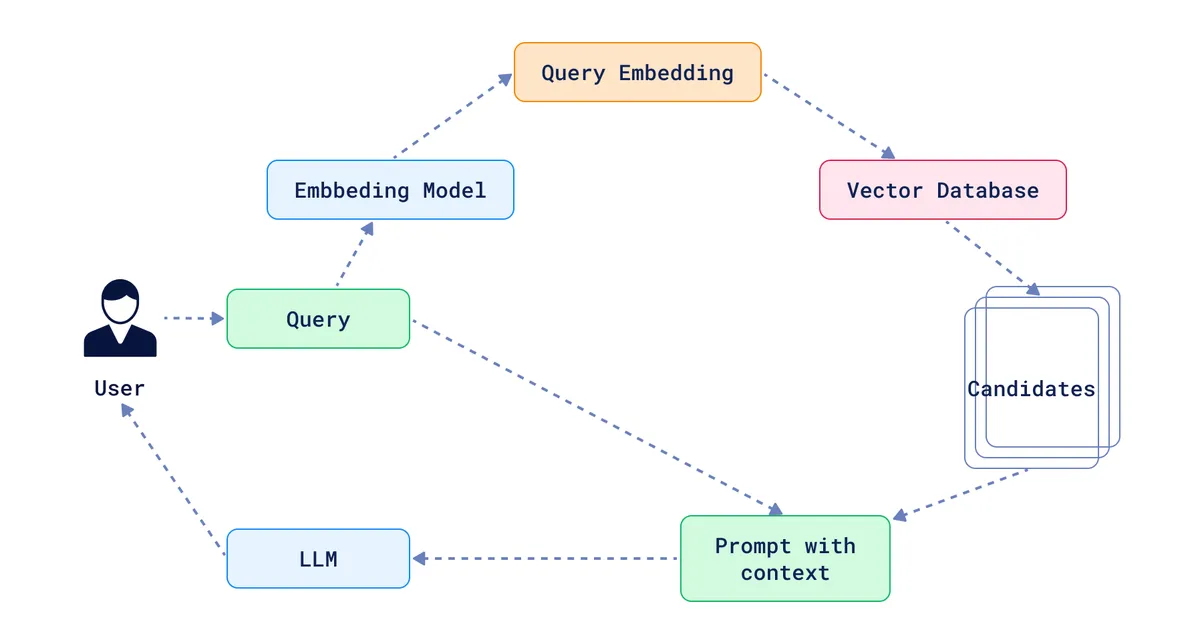
End-to-end pipeline for scraping any website and querying it through advanced RAG techniques. The goal: transform unstructured web data into a knowledge base queryable via natural language.
Architecture
flowchart LR
A[🌐 URL] --> B[Crawl4AI]
B --> C[LLM Extraction]
C --> D[Chunking]
D --> E[Embeddings]
E --> F[(Vector DB)]
F --> G[RAG Agent]
G --> H[💬 Response]
Intelligent scraping with Crawl4AI
Using Crawl4AI, an open-source crawler optimized for LLMs:
- LLM Extraction: Structured data extraction via prompts, without brittle CSS selectors that break on every site update
- LLM-optimized Markdown: Output directly usable by LLMs (automatic HTML cleanup)
- JavaScript support: Full rendering of React, Vue, Angular sites via headless browser
- GDPR handling: Automatic cookie consent and popup dismissal
- Deep crawl: Recursive exploration with page relevance scoring
Vectorization
Scraped content is transformed into vectors for semantic search:
| Component | Configuration |
|---|---|
| Chunking | Recursive character splitter (1000 chars, 200 overlap) |
| Embeddings | OpenAI text-embedding-3-small (1536 dimensions) |
| Vector Store (dev) | ChromaDB (local, fast) |
| Vector Store (prod) | Supabase pgvector (scalable, SQL queries) |
Chunking with overlap preserves context between segments:
flowchart LR
Doc[📄 Document] --> C1[Chunk 1<br/>1000 chars]
Doc --> C2[Chunk 2<br/>1000 chars]
Doc --> C3[Chunk 3<br/>1000 chars]
C1 -.->|200 chars overlap| C2
C2 -.->|200 chars overlap| C3
Advanced RAG techniques
Beyond basic RAG (retrieve → generate), several techniques improve response quality:
HyDE (Hypothetical Document Embeddings)
Generate a hypothetical document answering the question, then search for documents similar to this ideal response:
flowchart TB
Q[❓ User query] --> LLM[LLM generates hypothetical document]
LLM --> HDoc[📄 Fictional ideal document]
HDoc --> Emb[Hypothetical doc embedding]
Emb --> Search[Similarity search]
Search --> Results[📚 Relevant documents]
Query Augmentation & Multiple Query Generation
- Query Augmentation: Enrich the user query with synonyms and reformulations via LLM before embedding
- Multiple Query Generation: Generate multiple query variants to increase recall
Reciprocal Rank Fusion (RRF)
Combine results from multiple retrievers with intelligent weighting:
flowchart LR
Q[Query] --> R1[Retriever 1]
Q --> R2[Retriever 2]
Q --> R3[Retriever 3]
R1 --> |Rank A| RRF[🔀 RRF Fusion]
R2 --> |Rank B| RRF
R3 --> |Rank C| RRF
RRF --> Final[Weighted combined score]
Re-ranking
Refine final ranking with a cross-encoder model to improve precision.
Agentic RAG
The “Agentic RAG” approach goes beyond the classic linear pipeline. An LLM agent dynamically orchestrates the retrieval process:
flowchart TB
Q[Query] --> Agent[🤖 RAG Agent]
Agent --> Decide{Strategy?}
Decide --> |Reformulate| Rewrite[Query Rewriting]
Decide --> |Multi-query| Multi[Generate variants]
Decide --> |Direct| Retrieve[Retrieval]
Rewrite --> Retrieve
Multi --> Retrieve
Retrieve --> Eval{Sufficient results?}
Eval --> |No| Agent
Eval --> |Yes| Generate[Response generation]
Generate --> Response[💬 Final response]
The agent can:
- Decide on strategy: Choose between direct retrieval, reformulation, or multiple query generation based on question complexity
- Self-evaluate: Judge whether retrieved documents are sufficient to answer
- Iterate: Relaunch search with a different strategy if results are insufficient
- Orchestrate: Adaptively combine multiple techniques (HyDE + RRF + re-ranking)
Tech stack
- Scraping: Python, Crawl4AI, Playwright
- Vectorization: LangChain, ChromaDB, Supabase pgvector
- LLM: OpenAI API (GPT-4, text-embedding-3-small)
- Orchestration: Python asyncio for parallel crawling
Challenges
- Dynamic sites: Some sites load content via JavaScript with infinite scroll, requiring an automatic scrolling strategy
- Rate limiting: Implementation of adaptive delays and header rotation to avoid blocking
- Chunking quality: Finding the right size/overlap balance to preserve context without creating duplicates
- Embedding costs: Optimizing token count by filtering irrelevant content before vectorization
Results
- Able to scrape and index 50+ page websites in minutes
- Accurate contextual responses thanks to advanced RAG techniques (HyDE significantly improves relevance)
- Reusable pipeline for various use cases: technical documentation, e-commerce sites, knowledge bases